












Data Compare for SQL Server
O Data Compare para SQL Server é uma ferramenta que permite comparar e sincronizar dados nos bancos de dados do SQL Server. Você pode usá-lo para migração de dados, auditoria, verificação de replicação, preenchendo bancos de dados de desenvolvimento com dados de produção, etc.
Fabricante: xSQL Software
Descrição detalhada do produto
SOLICITE SEU ORÇAMENTO
Descrição detalhada do produto
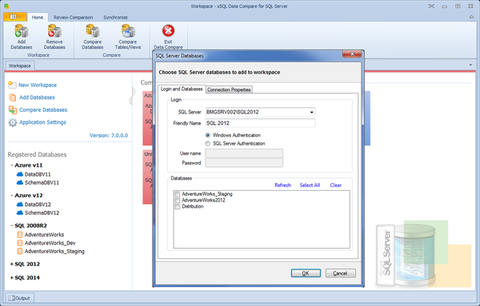
O Data Compare for SQL Server suporta SQL Server 2017, 2016, 2014, 2012, 2008 / 2008R2, 2005 e 2000, bancos de dados Microsoft Azure v11 e v12 e está disponível gratuitamente como uma Lite Edition totalmente funcional.
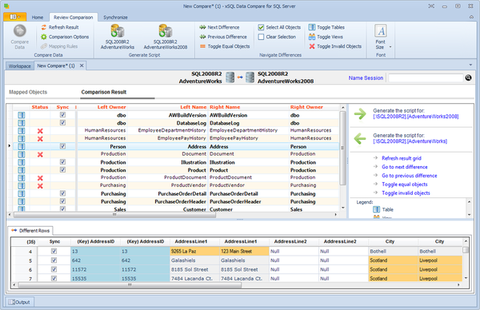
- Compare dados em dois bancos de dados do SQL Server, tabelas e visualizações
- Gere scripts de sincronização t-sql seguros
- Mapeamento personalizado de esquema de banco de dados, tabelas e tipos de dados
- Interface gráfica moderna e eficiente
- Comparação com um clique
- Tamanho variável da transação
- Utilitário de linha de comando para comparação autônoma
- Suporte no SQL Server 2000-2017 e SQL Azure v11/v12 no local
- Mecanismo de comparação - mecanismo de comparação robusto e altamente eficiente compara milhões de linhas rapidamente, enquanto controla rigidamente a utilização de recursos. Não há limite técnico no tamanho dos bancos de dados que o SQL Server Data Compare pode sincronizar.
- GUI moderna - a GUI do SQL Server Data Compare reflete os padrões mais recentes no design da interface do usuário. Faixa de opções sensível ao contexto, painéis de ação com descrições claras, implementação assíncrona de operações demoradas, informações detalhadas sobre o progresso e muito mais.
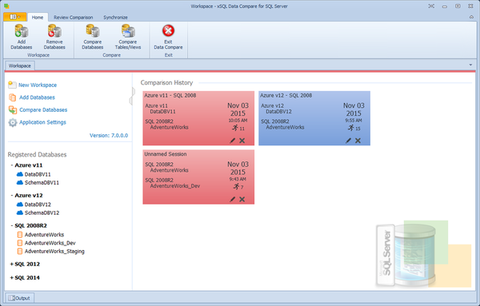
- Comparação com um clique - o SQL Server Data Compare mantém um histórico de sessões de comparação. Uma sessão é um ambiente persistente que contém todos os dados relacionados a uma operação de comparação, incluindo bancos de dados e as respectivas credenciais, opções de comparação, regras de mapeamento, objetos excluídos e muito mais. Permite que o usuário final repita uma comparação com um único clique. As opções controlam a maneira como as sessões são classificadas e o número máximo de sessões que persistem.
- Mapeamento personalizado - o recurso de regras de mapeamento permite personalizar a maneira como os objetos de banco de dados do SQL Server são pareados. As regras de mapeamento incluem: "Regras de mapeamento de esquema" que determinam como os esquemas do banco de dados são mapeados; "Regras de mapeamento de nomes" que determinam como os nomes dos objetos de banco de dados são mapeados; e "Regras de mapeamento de dados" que determinam como os tipos de dados sql são mapeados.
- Chaves de comparação personalizadas - você deseja comparar tabelas ou visualizações do banco de dados, mas elas são mostradas como não comparáveis porque não há chave primária ou índices exclusivos definidos nelas? Depois que o xSQL Data Compare para SQL Server analisar o esquema do banco de dados, você poderá definir uma chave exclusiva (qualquer combinação das colunas dessa tabela) para usar na comparação de dados sql. As linhas serão emparelhadas com base na chave selecionada.
- Utilitário de linha de comando - o utilitário de linha de comando SQL Data Compare, altamente configurável e incluído, permite agendar operações de comparação e sincronização de dados sql através do Agendador de tarefas do Windows, Agendador do SQL Server etc.
- Controle total sobre a comparação e sincronização - uma ampla variedade de opções oferece controle granular sobre o comportamento do mecanismo de comparação de banco de dados sql. Comparando visualizações de banco de dados junto com tabelas de banco de dados sql, analisando dependências de tabela e organizando o script de sincronização t-sql adequadamente, comparar bancos de dados sql com agrupamentos diferentes são apenas algumas das opções disponíveis.
- Manipulando bancos de dados grandes - algoritmos customizados lidam com a serialização de linhas de dados e fragmentos de script t-sql conforme necessário, garantindo um controle rigoroso da utilização da memória.
- Mecanismo de execução de script - o mecanismo proprietário inteligente de execução de script garante que scripts t-sql muito grandes, incluindo scripts para colunas binárias e colunas de texto grandes, sejam executados com êxito, fornecendo informações de progresso contínuas e permitindo a interrupção segura do script, se necessário.
- Tratamento de erros - o tratamento sistemático de erros visa eliminar resultados inesperados / inexplicáveis. Erros não críticos são registrados e relatados, mas não interrompem a operação. Os erros são relatados através de caixas de diálogo ou impressos no painel de saída. Um log de erro completo é criado.
Obrigado! Logo entraremos em contato!
Baixe o Guia Software.com.br 2024

Nossos Clientes


































